In the fast-paced world of finance, accurate and timely analysis can mean the difference between a successful investment and a missed opportunity. Traditionally, powerful models like GPT-4 have been the go-to for such tasks, thanks to their impressive accuracy and versatility. However, these models come with a hefty price tag. What if we could achieve similar results at a fraction of the cost? This blog explores how we fine-tuned a language model to deliver high-quality financial analysis without breaking the bank.
The Challenge
Financial analysis is a cornerstone of investment decision-making. With the increasing complexity of financial markets, leveraging advanced language models to analyze vast amounts of data has become essential. GPT-4, known for its unparalleled performance, is often used for this purpose. However, its high computational requirements and associated costs can be prohibitive. We aimed to find a more cost-effective solution without sacrificing accuracy.
Our Objective
Our goal was simple yet ambitious: fine-tune a language model to provide financial analysis comparable to GPT-4 while significantly reducing costs. We focused on generating reliable stock recommendations—buy, sell, or hold—based on financial metrics, with an emphasis on maintaining accuracy and conviction.
The Approach
DATA GENERATION
Creating a robust dataset is the first step in training any machine learning model. We generated a dataset comprising financial metrics, tailored prompts, and GPT-4’s recommendations along with their conviction scores. This dataset was designed to be both comprehensive and representative of real-world financial scenarios, ensuring our model could learn effectively.
Our data generation process involved meticulously curating financial data to reflect realistic market conditions. We included approximately 1,000 stock tickers from prominent US-based companies, including those in the S&P 500. This diverse dataset allowed us to cover various industries and market conditions, providing a well-rounded training base for our model.
FINE-TUNING THE MODEL
To adapt our language model to the specific requirements of financial analysis, we employed a technique called Low-Rank Adaptation (LoRA). This approach allowed us to fine-tune the model efficiently, aligning its outputs with the recommendations provided by GPT-4. The fine-tuning process was iterative, involving multiple rounds of optimization to ensure the model’s outputs were as accurate as possible.
We conducted the training over 500 epochs, with an 80-20 split between training and validation data. Given the length and complexity of the prompts, we opted to use a 4-bit version of the model to manage computational requirements effectively.
Architecture
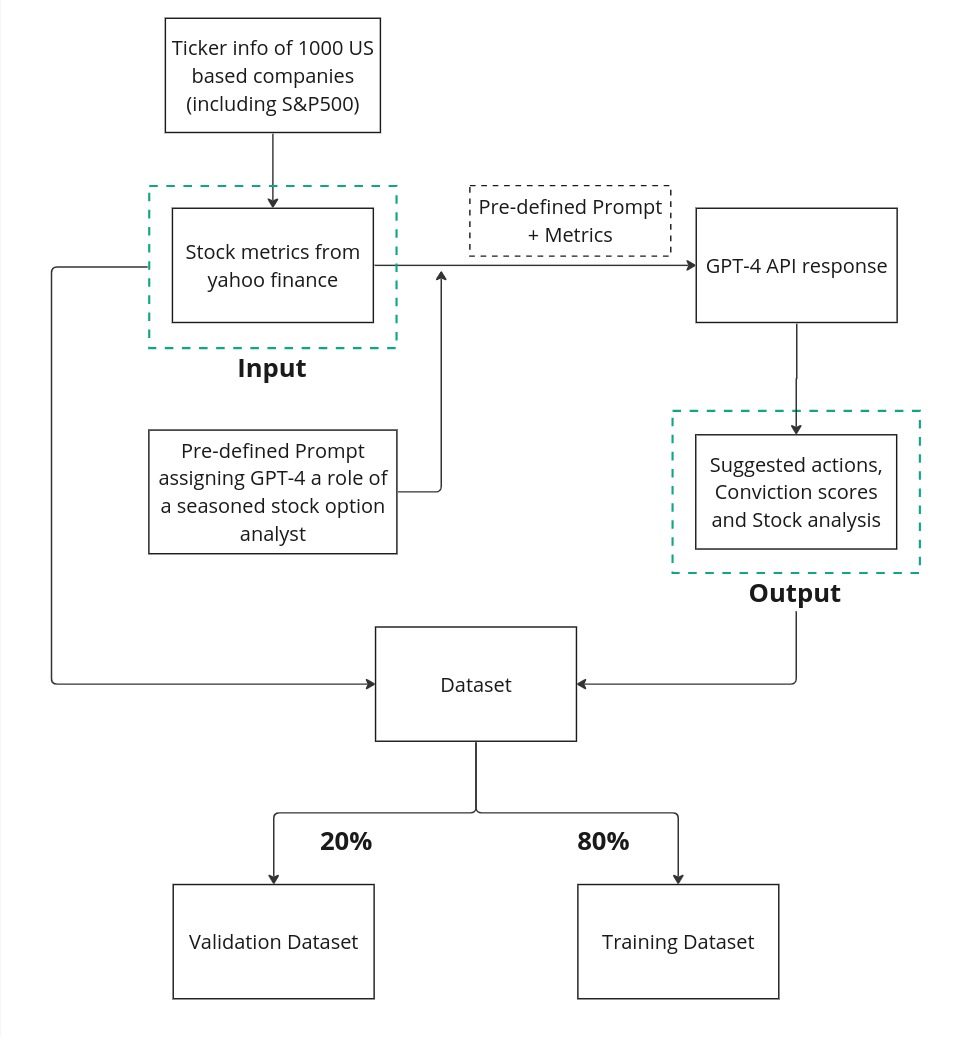
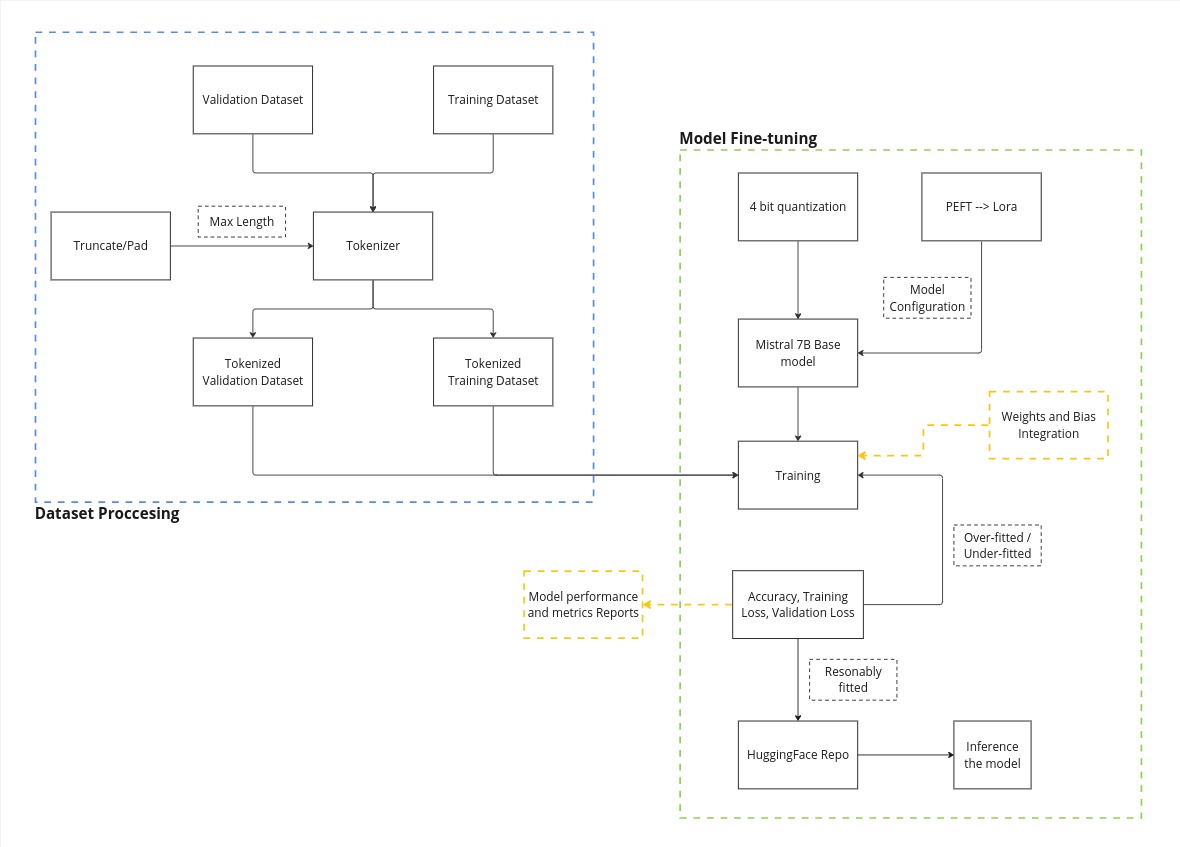
Infrastructure Setup
Our infrastructure was key to balancing performance and cost. We utilized hardware from Runpod and partnered with QWAK, leveraging the following setup:
- Model: Fine-tuned Mistral 7B
- GPU: 2 X NVIDIA A100 with 80 GB VRAM
- CPU: 8 cores
- RAM: 117 GB
This setup ensured we had the computational power needed for training and deployment without excessive costs. The combination of robust hardware and efficient model adaptation techniques enabled us to achieve high performance without incurring prohibitive expenses.
Deployment Architecture

Comparing Performance and Costs
ACCURACY AND EVALUATION
Once fine-tuned, we rigorously tested our model on unseen financial data. Our evaluation metrics included accuracy, validation loss, training loss, and the conviction scores for each recommendation type. The fine-tuned model demonstrated robust performance, closely mirroring GPT-4’s accuracy in many scenarios.
We paid close attention to the model’s ability to handle different market conditions and diverse financial scenarios. This comprehensive evaluation ensured that our model was not only accurate but also versatile, capable of providing reliable insights across a wide range of financial contexts.
COST ANALYSIS
The most striking advantage of our model over GPT-4 is the cost. Here’s a detailed breakdown:
- Cost per 1,000 tokens:
- GPT-4: $0.03
- Our model: $0.00368
- Cost per million tokens:
- GPT-4: $30.00
- Our model: $3.68
The training process was also economical:
- Training Cost: $2
- Dataset Generation: $15
- Infrastructure for API Service: $10 per day
- Hosting Instance: ml.g4dn.xlarge (current cost: $0.7364/hour)
- Number of API Calls per Hour: 200
- Cost per API Call: $0.003682
Deployment
Deploying our model involved several steps to ensure smooth operation and accessibility:
- Loading the Model: We loaded the fine-tuned model into our Huggingface repository.
- AWS Sagemaker Deployment: We used an ml.g4dn.xlarge instance for deployment.
- API Endpoint Configuration: We set up an API endpoint to handle inputs and outputs.
- AWS Lambda Integration: We used AWS Lambda to invoke functions that process user input through the model and return the results to the API endpoint.
This deployment process was designed to be efficient and scalable, ensuring that users could access the model’s capabilities without delays or interruptions.
Real-World Application
The fine-tuned model excelled in real-world tests, providing accurate stock recommendations and conviction scores. Although the initial accuracy was around 85%, we are confident that with more extensive training data, this can be further improved.
Our model’s performance in real-world scenarios highlighted its potential to revolutionize financial analysis. By providing reliable recommendations at a fraction of the cost, our model makes advanced financial insights accessible to a broader audience. This democratization of high-quality financial analysis can empower individual investors and small firms, leveling the playing field in the financial markets.
Product Demo: Visual Guide and Explanation
Conclusion
Our project demonstrates that cutting costs does not mean cutting corners. By fine-tuning a language model, we achieved a balance between cost efficiency and performance, making advanced financial analysis accessible to a broader audience. This approach can significantly benefit financial analysts and investors by providing reliable insights without the heavy computational burden associated with models like GPT-4.
The future of financial analysis lies in leveraging powerful yet cost-effective models, and our work with this fine-tuned model is a step in that direction. Whether you’re a seasoned financial analyst or an investor looking for reliable data-driven insights, fine-tuned models like ours offer a promising solution.
In the end, it’s not just about having the best tools but about using them smartly to achieve the best results. And that’s exactly what we’ve done with our model. Through meticulous data generation, efficient fine-tuning, and strategic deployment, we’ve created a tool that delivers high-quality financial analysis without high costs, setting a new standard for the industry to achieve the best results. And that’s exactly what we’ve done with our model.